Узкие места SQL в EF Core: что проверять в первую очередь
Если приложение на EF Core демонстрирует высокую задержку на уровне базы данных, начинайте с логов SQL и реального плана выполнения. В статье «Ускоряемся в Entity Framework Core» на Хабре автор DmitryNBoyko акцентирует внимание на том, что видимый SQL — лучший старт для оптимизации, а не гипотезы о причинах.
Частые причины медленной работы — избыточные выборки целых сущностей, N+1-запросы при ленивой загрузке и включения (Include), а также трекинг большого количества объектов. Перед изменениями зафиксируйте поведение через профайлер или встроенное логирование EF Core.
Диагностика и профилирование SQL в EF Core
Получить SQL, который сгенерировал EF Core, можно прямо из IQueryable через ToQueryString() или включив логирование SQL через DbContextOptionsBuilder.LogTo. Сравнивайте полученный текст с реальным профилем в СУБД и смотрите, какие индексы используются.
Не ограничивайтесь только количеством запросов: анализируйте их стоимость на стороне СУБД и используйте реальные execution plans. Общие подходы к анализу и оптимизации запросов описаны на странице Википедии о оптимизации запросов СУБД; это полезно, чтобы соотнести поведение LINQ с уровнями оптимизации в СУБД: Оптимизация запросов СУБД.
Сокращение объёма данных: проекции и выбор полей
Частая ошибка — запрашивать полные сущности вместо нужных полей. Используйте Select для явной проекции в DTO или анонимный тип, чтобы сгенерировать компактный SQL с конкретными колонками.
Проекции уменьшают трафик и время парсинга результата на стороне клиента. Если нужно только агрегатное значение или подмножество колонок — делайте это в LINQ, а не загружайте сущность целиком и затем выбирайте поля в памяти.
Избегание N+1: правильные Include и AsSplitQuery
N+1 возникает, когда навигации загружаются отдельными запросами. Решение — включать связанные сущности через Include или писать один запрос с join/проекцией. Но массовое Include может привести к дублированию строк и большому объёму данных.
Для больших наборов с множественными Include рассмотрите AsSplitQuery в EF Core: он разбивает Include в несколько запросов, снижая мультипликацию строк и память, но увеличивает количество round‑trip. Выбор между одиночным join и split‑query зависит от размера выборки и профиля СУБД.
Трекинг, кеширование и управление контекстом
AsNoTracking() — простой и эффективный способ сократить накладные расходы трекинга для операций чтения. Для страниц списка и бекэнда с высокой нагрузкой используйте безтрекинговые запросы, чтобы избежать расхода памяти и времени на построение ChangeTracker.
Если требуется обновление сущности после чтения, подумайте о частичном трекинге: сначала проекция для отображения, затем отдельный, небольшой запрос для модификации. Также контролируйте время жизни DbContext: короткие контексты лучше для веб-запросов, а длинные — для батчевых операций.
Когда перейти к ручному SQL и индексам
Иногда LINQ-генерация слишком сложна и производит неэффективный SQL. В таких случаях оправдано использовать FromSqlRaw/ExecuteSqlRaw или хранить запросы в виде представлений (VIEW) и вызывать их из EF. Это уменьшит сложность и даст полный контроль над планом выполнения.
Не забывайте про индексы: оптимальный SQL без подходящих индексов всё равно будет медленным. Согласуйте изменения на уровне модели с DBA и проверяйте планы после добавления индексов.
Практическая проверка и тестирование оптимизаций
Любое изменение запросов должно сопровождаться A/B‑тестированием на тестовом окружении с производственными объёмами данных. Измеряйте latency и throughput до и после, фиксируйте изменения плана выполнения. В идеале автоматизируйте регрессионное тестирование запросов в CI, чтобы не допустить деградации при рефакторинге.
Короткий чеклист для быстрого аудита:
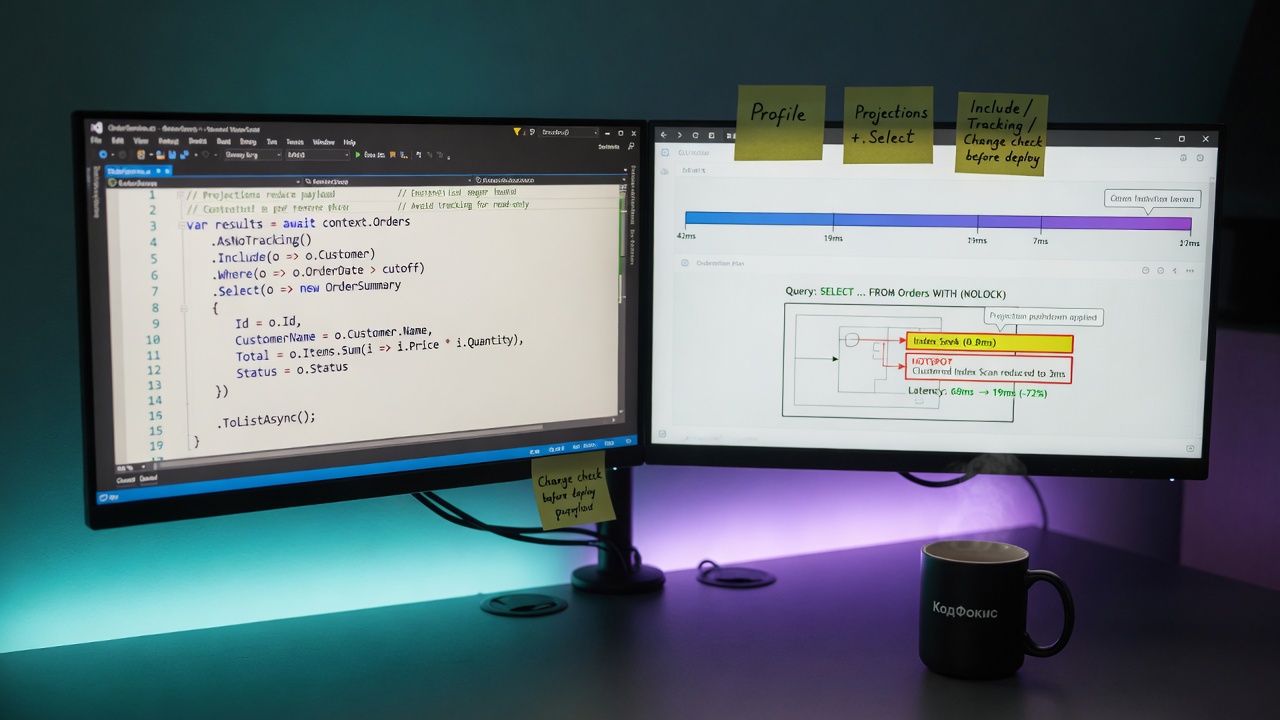
- Сравнить SQL из ToQueryString() с профайлером СУБД
- Заменить полные сущности на Select‑проекции
- Использовать AsNoTracking() для читаемых сценариев
- Проверить AsSplitQuery для больших Include
Следуя этим шагам и руководству из упомянутой статьи на Хабре, вы получите системный подход к оптимизации запросов в приложениях на Entity Framework. Комбинация профилирования, аккуратных проекций, контроля трекинга и продуманного использования Include/AsSplitQuery даёт наибольший эффект без перехода на сырой SQL.